제목 앞의 * 표시는 중요하다는 의미입니다.
운영체제 : 컴퓨터 하드웨어를 관리하는 소프트웨어
컴퓨터 하드웨어 : CPU, Memory, I/O 장치
=> 운영체제가 하는 일 : CPU 관리 / Memory 관리 / I/O 장치 관리
1. Program vs. Process
- Program
: disk .. 또는 file system에 저장된 실행 파일
- Process
: Program은 실행이 되면 Memory로 loading되어 실행되는데, 이때 메모리로 로딩되어 실행되는 실행 주체가 Process.
: Basic unit of execution(실행) and scheduling.
: A process is named using its process ID (PID, integer(숫자)임)
*Scheduling
: Process 여러 개의 실행 순서를 결정하는 작업.
2. Process Concept
What is Process?
(1번 내용과 동일함.)
- Program의 instance(인스턴스).
- 지금은 Process보다 더 작은 단위인 thread가 나왔지만, 유닉스가 처음 만들어졌을 때는 process가 가장 작은, scheduling의 기본 단위였음.
+)
mainframe 시절 -> Process가 아니라 Job이라고 불렀음.
IBM에서 만든 운영체제(최초의 OS다운 OS) 시절 -> Job이 아니라 Task라고 부름.
=> 유닉스를 만들면서 Process라고 정의한 것.
=> 요즘은 Windows, Unix, Linux 다 Process라고 하고, RTOS에서는 task라고 보통 부름.
*3. Process Address Space
자주 나오니까 꼭 이해해두기.

0번지부터 위로 올라감.
1. text segment (=code segment)
- 가장 밑 부분.
- CPU의 명령어들이 존재하고, 순차적으로 이 명령어들이 수행됨.
- ex) jump, function call .. 등이 존재.
2. data segment
- static data 들이 저장되는 곳.
- static data(전역변수) : 프로그램이 실행되는 동안 항상 메모리를 차지하고 있는 변수.
+)
function 내부에 존재하는 local 변수들은 여기가 아니라 stack에 저장됨.
이 지역변수(local 변수)들은 function이 수행될 때 임시적으로 stack에 생겼다가 function이 끝나고 나면 사라지는 방식으로 동작함.
3. heap
- Dynamically allocated memory, 즉 DMA(Dynamic Memory Allocation, 동적 메모리 할당)에 사용되는 메모리 영역.
- ex) C++ -> new / C -> malloc : 이런 함수에 의해 동적으로 생성됐다 없어지는 메모리 영역이 heap.
4. stack
- 거꾸로 증가했다 감소했다 하는 형태로 stack이 늘어났다 줄어들었다 함.
- stack을 이용해 function call할 때마다 아래 예와 같이 stack이 증가하고,
- function에서 return 되면 stack은 다시 감소함.
=> 함수가 호출이 되면, return address, 함수의 parameters, 함수의 지역변수들이 stack에 메모리가 잡힘.
(전역 변수(static 변수)는 data segment에 저장됨!)
- ex) func()를 호출하면 어떤 일이 일어나는가. (func() 호출 전 stack의 top은 위 그림의 SP라고 했을 때)

1. stack의 제일 top에 return address가 저장됨. (func()를 수행하고 나서 돌아갈 return address 저장)
2. func()가 parameter로 사용할 a, b라는 값을 stack에 넣음. (여기서 10, 20)
(C인 경우 - 위와 같이 b부터(뒤에서부터) parameter를 집어넣어서 stack에 20이 들어간 후 10이 들어감.
C++의 경우 - a부터(앞에서부터) parameter가 들어갈 듯. 맥락상.)
3. 그 다음에 func() 호출하면 func()를 수행하는 시점에서 b의 위치에 있는 20, a의 위치에 있는 10을 사용함.
4. 그러면 func() 내부로 들어가서 local 변수 c,d를 저장할 공간을 만듦.
-> stack pointer (SP)는 d라는 변수를 위한 공간까지 증가하는 것.
5. 그 후 c=20;에서 c를 위한 자리에 20을 집어넣는 것.
+) Recursion에서 끝나는 조건 설정 안 해두면 Stack Overflow가 나서 Process가 종료되는 이유
function call을 한 번 할 때마다 stack이 증가하는데,
recursion은 계속 자기 자신을 호출하는 거니까 계속 stack이 증가해서 언젠가 stack이 부족하게 되는 것.
정리
- 가장 아래 번지가 0번지부터
- Stack은 제일 위에서 작아지는 형태로 stack이 커짐. (거꾸로임)
+ 모든 프로세스가 제일 밑에 번지가 0번지(0x00000000)임.
*4. State Diagram
*아주 중요*
Process는 state(상태)라는 것을 가짐. 이 state diagram은 다음과 같다.
Program이 실행이 되면 Process라는 것이 하나 만들어짐.
(Program 하나 실행될 때 여러 개의 Process가 만들어질 수도 있으나 일단 하나가 만들어진다고 생각해봅시다.)
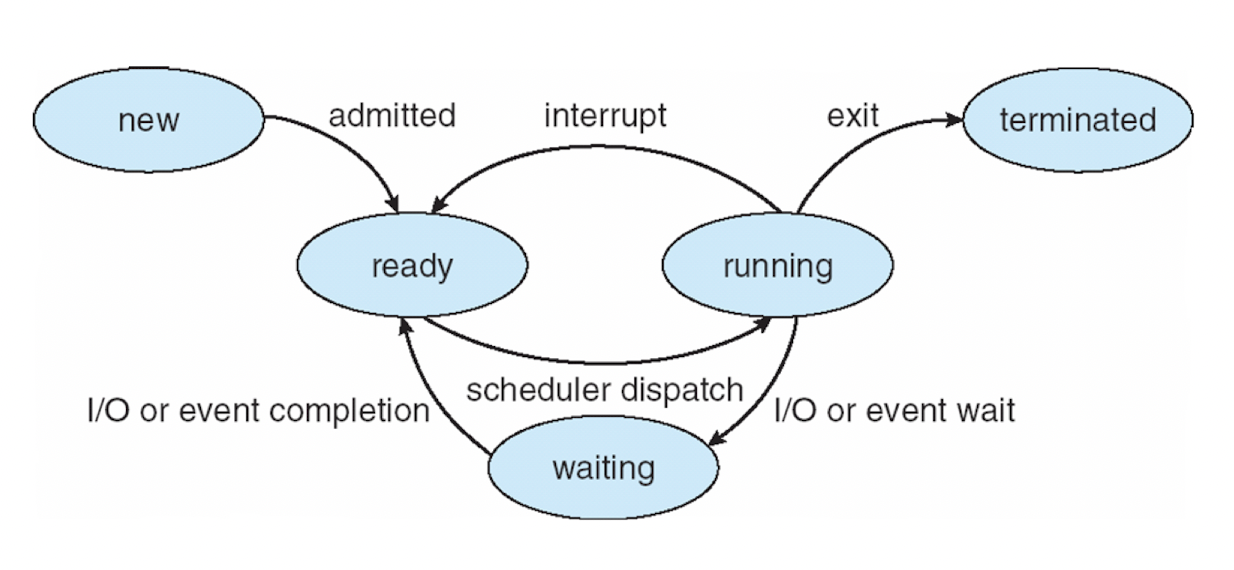
1. new
- 가장 처음 state. Process가 막 만들어지는 단계.
2. ready
- Process가 다 만들어져서 실행 가능한 상태가 된 것. 준비됐다는 뜻.
- Scheduler dispatch
- Scheduling
: ready state에 있는 process 중 하나를 고르는 작업.
- Dispatch
: scheduled 된 process를 실행시키기 위해 그 process를 CPU에 올리는 작업.
- Scheduling과 Dispatch를 수행하는 주체
: 운영체제인데, 더 구체적으로 운영체제 내부에 이런 작업을 하는 것을 scheduler라고 함.
-> 그래서 위 그림에서 scheduler dispatch라고 표현한 것.
- Interrupt
- scheduler dispatch해서 running 상태가 되어 CPU에서 막 수행이되다가 interrupt가 걸리면 자기가 하던 일을 저장하고 다시 ready 상태가 됨.
- interrupt가 걸리면 자기가 하던 일을 저장하고 interrupt handler로 jump해서 더 이상 본인이 계속 수행되는게 아니니까.
3. running
- 프로그램이 ready 상태에서 dispatch가 되어 CPU에 올라가서 수행이 되는 단계.
4. terminated
- Process가 수행되다가 끝나면 terminated 상태가 되어 이 process를 종료시키는 작업을 함.
- ex) 이 process가 open해 놓은 파일들 다 닫고, 이 process가 차지하던 메모리를 반환하고, ..
- 그 후 terminated state에서도 아예 이 process가 사라지게 됨.
5. waiting
- I/O가 발생하길 기다리는 상태.
ex) running하고 있다가 keyboard에서 키가 입력이 돼야 수행되는 상태.
- I/O가 끝나기를 기다리는 상태
ex) running 상태에서 내가 disk에서 데이터를 읽어야해서 disk I/O를 요청했을 떄.
Disk I/O 작업은 시간이 오래 걸리니까 이 I/O가 끝날 때까지 다른 애가 수행돼서 나는 CPU에서 쫓겨나야함.
이 때도 waiting 상태가 되어 Disk에서 데이터가 다 읽혀지기를 (Disk I/O가 끝나기를) 기다려야 함.
=> I/O가 발생하기를 기다리거나, I/O가 발생되기를 기다리거나 ..
(ex. 키보드가 눌렸다던지, 외부에서 패킷이 도착했다던지, Disk 작업 요청한 게 끝났다던지
이런 event가 발생되기를 기다리는 상태가 waiting 상태.
+) waiting vs ready
이 차이도 확실하게 기억하기.
waiting
: I/O나 event가 발생하기 전까지는 더 이상 자발적으로 수행될 수 없는 상태. 그러니 기다릴 수 밖에 없는 것.
ready
: 현재 수행될 수 있는 상태인데, 다른 애가 (CPU에서) 수행되고 있으니까 내가 schedule 되기를 기다리는 상태.
=> ready, running, waiting 상태를 왔다갔다하면서 process가 실행이 된다.
5. Process Control Block (PCB)
- PCB
: 운영체제가 process를 관리를 위해, process에 대한 정보를 저장하고 관리하는 data structure.
: Process와 관련된 정보들의 예 : 어떤 상태에 있는지, waiting이라면 어떤 I/O를 기다리는지, 키보드 입력을 기다리는지 .. 등
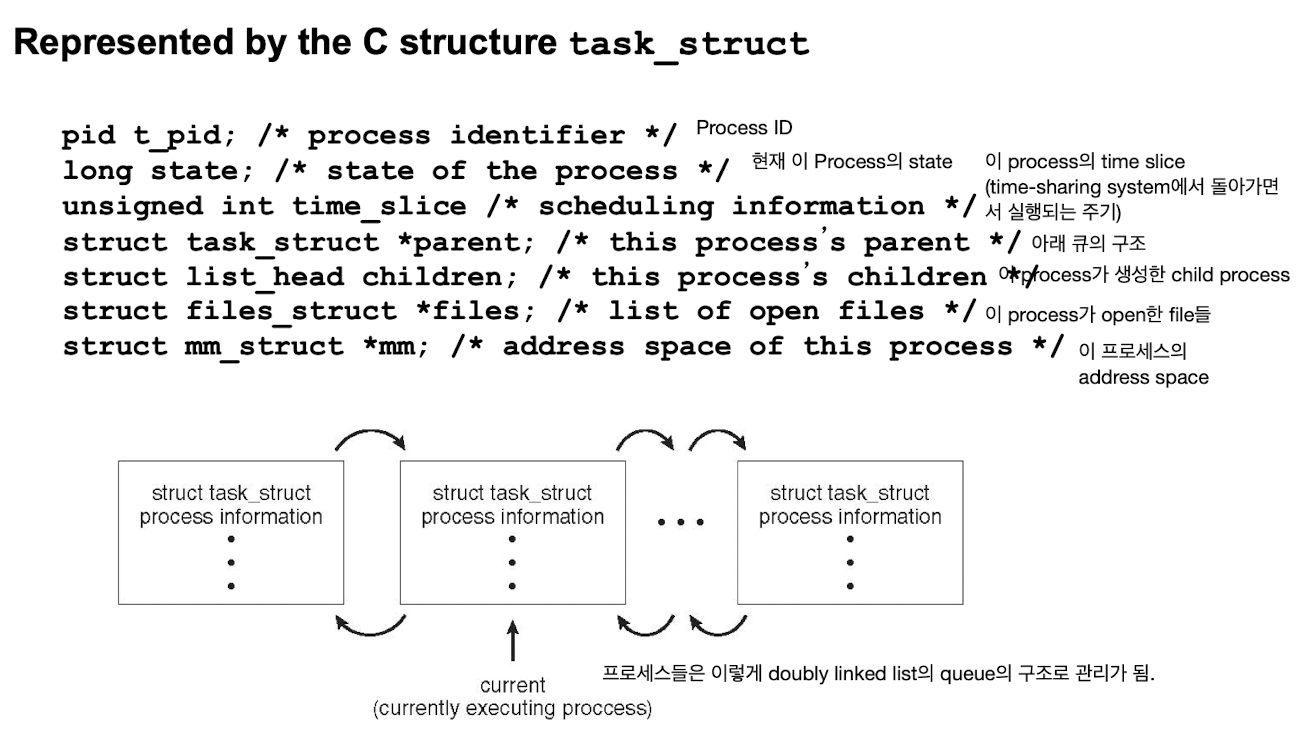
- task_struct in Linux
: 이 PCB가 Linux 에서는 task_struct라고 하는 구조체로 되어있음.
: 이 구조체의 주요 멤버 몇 가지

*6. Context Switch
CPU Switch라고도 하지만, 보통 Context Switch라는 말로 더 불림.
- Context Switch
: CPU의 상태 or context가 바뀌는 것.
: ex) ready -> running, running -> waiting ..
: ex) CPU는 하나인데 process 0이 수행되다가 process 1이 수행되면 CPU의 상태가 switch되는 것.
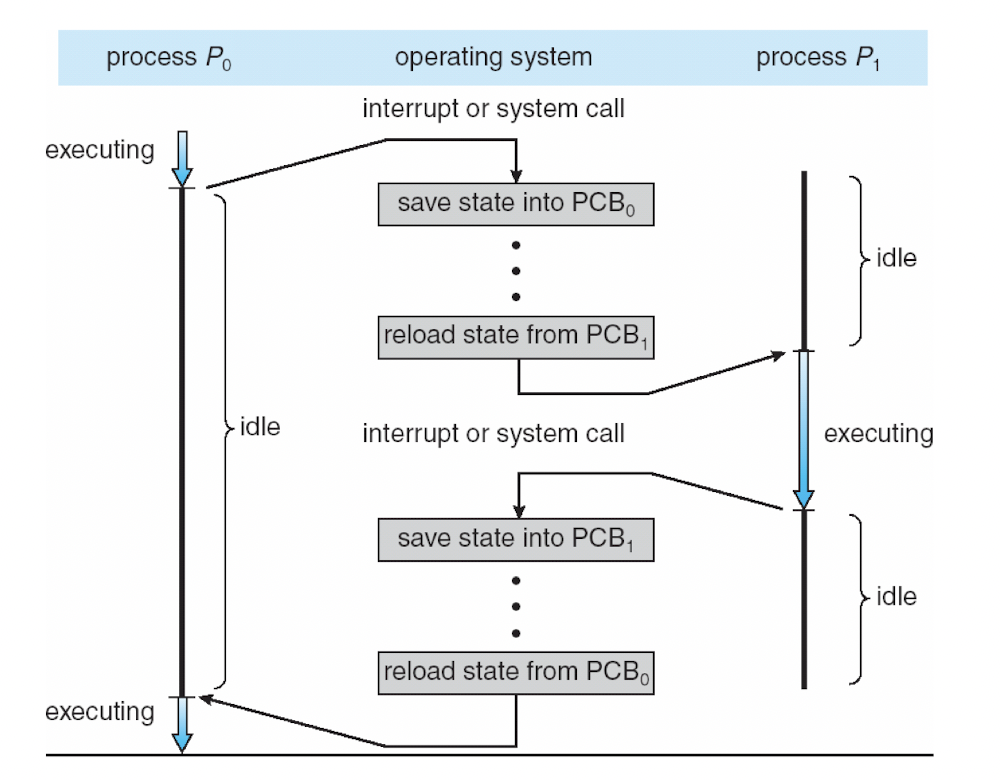
그림 설명) P0 -> P1 -> P0 의 과정.
1. executing P0
: 현재 Process 0 (P0)가 실행 중.
2. Interrupt of system call
: Hardware Interrupt가 불리거나 해당 프로세스가 system call을 요청 -> OS가 수행됨.
3. Save state into PCB0
: 현재 수행 중인 process의 상태(state)를 PCB0에 저장.
상태(state)를 저장하다
= 이 예에서 보면, CPU의 context를 P0에서 P1으로 바꾸어야하는데, (= OS가 P1을 scheduling해서 dispatch해야 하는데,)
이 CPU의 context는 CPU에 저장되어 있는 data들, 즉 CPU에 존재하는 레지스터들을 의미함.
따라서 CPU에서 P0가 실행 중일때는 CPU에 있는 여러 register들의 데이터들이 P0와 관련된 것들로 존재했기 때문에
save state(state를 저장한다는 것)는 이 CPU의 Register들의 값을 저장한다는 것을 의미함. (이 경우 PCB0에 저장함. P0니까)
(~ .. 운영체제가 본인 할 일 함 .. ~)
4. Reload state from PCB1
: P1으로 CPU의 context를 바꾸어야 하는데, P1의 context는 PCB1에 저장되어있으니까 여기서 꺼내서 CPU에 있는 레지스터들로 가져다 넣음.
5. executing P1
: 그러면 P1이 이전에 수행되던 상태 그대로, 그때부터 다시 실행이 됨.
6. Interrupt or system call
: P1이 수행되다가 다시 hardware interrupt가 발생하거나 application이 system call을 요청하면
-> 운영체제가 수행되고
-> 운영체제가 다시 P1이 수행되던 상태를 PCB1에 저장함. (수행되던 상태 = CPU의 레지스터들의 값)
(~ .. 운영체제가 본인 할 일 함 .. ~)
7. Reload state from PCB0
: 다시 P0가 수행되어야하기 때문에 P0를 scheduling해서 dispatch함.
: 따라서 PCB0에 아까 저장했던 CPU 레지스터들의 값으로 다시 CPU의 레지스터들을 복구(relaod)함.
8. executing P0
: 아까 P0 실행했던 상태 그대로 P0가 다시 실행이 됨.
: P0 입장에서는, 자기가 실행되다가 P1이 실행되다가 다시 자신이 실행됐지만, 결국 자신이 그냥 쭉 실행된 것처럼 수행 가능.
+) Reload
: reload한다는게 PCB에 있는 데이터를 레지스터로 옮기는건데,
더 정확하게 얘기하면, PCB에는 해당 프로세스에 대한 정보가 엄청나게 많이 있음.
그 중에 레지스터들의 값을 저장하는 그런 부분이 있음. 그 부분을 CPU 레지스터에다가 넣는거나 그 부분에다가 CPU 레지스터들의 값을 복원하는 것.
PCB에는 엄청나게 다양한 데이터들이 있다고.(위에 그림) 이 그림의 모든 부분을 CPU 레지스터에다가 넣는게 아니라 이 그림의 PCB 내용 중에 이 CPU
register 부분에다가 저장하고 이 부분을 다시 reload하는것.
+) 추가 설명
: CPU에서 제일 중요한 레지스터들 PC, IR, SP, PSW, 그리고 기타 general purpose register들.
이 general purpose register들은 +,-, *, %, or, and, Shift .. 이런 연산을 했을 때의 임시적인 값을 저장함.
따라서 이런 레지스터에 있는 값들이 이제 다른 프로세스 껄로 바뀌어야하니까 그 원래 프로세서꺼를 일단 메모리에 임시적으로 저장을 해야겠지.
그랬다가 내가 다시 이 프로세스를 실행하려면 이 저장된 걸로 CPU에 있는 레지스터의 값을 바꾸겠지
그러면 이제 똑같은 상태에서 실행이 되는거지.
+) dispatch가 결국 context switching의 어떤 하나의 작업인 것.
- Administrative overhead
: overhead = 수수료와 유사한 개념.
-> Context Switching을 하게 되면 레지스터들을 PCB에 저장하고, PCB에서 복구하는 것 뿐만 아니라,
Cache memory가 flush됨. (Cache memory에는 지금 현재 그 프로세스가 수행되기 위해서 필요한 그런 명령어들이 다 존재
하는데, 이것들이 새로운 프로세스의 내용으로 다 바뀌어야함.)
-> 성능 상 엄청 큰 부담.
: 하지만 그럼에도 불구하고 Context Switching을 하는 게 response time의 측면에서 훨씬 우수한 성능을 보이기 때문에 함.
(Ch1. OS history 에서 Batch -> Multiprogramming -> Time Sharing 부분 참고)
- Context switch overhead is dependant on hardware support
: Context switch overhead는 수수료니까 줄이는 것이 좋은데, 이걸 줄이는 작업 성능은 CPU마다 다름.
: 현재 전 세계에서 가장 빠른 CPU는 intelx86. (64bit짜리)
-> 여기서 성능을 더 높이고 싶으면 CPU 여러개 쓰거나, 네트워크로 연결하거나 해서 대용량으로 만들 수 밖에 없음.
- application마다 다르겠지만, 보통 초당 100s or 1000s 만큼의 switches를 수행함.
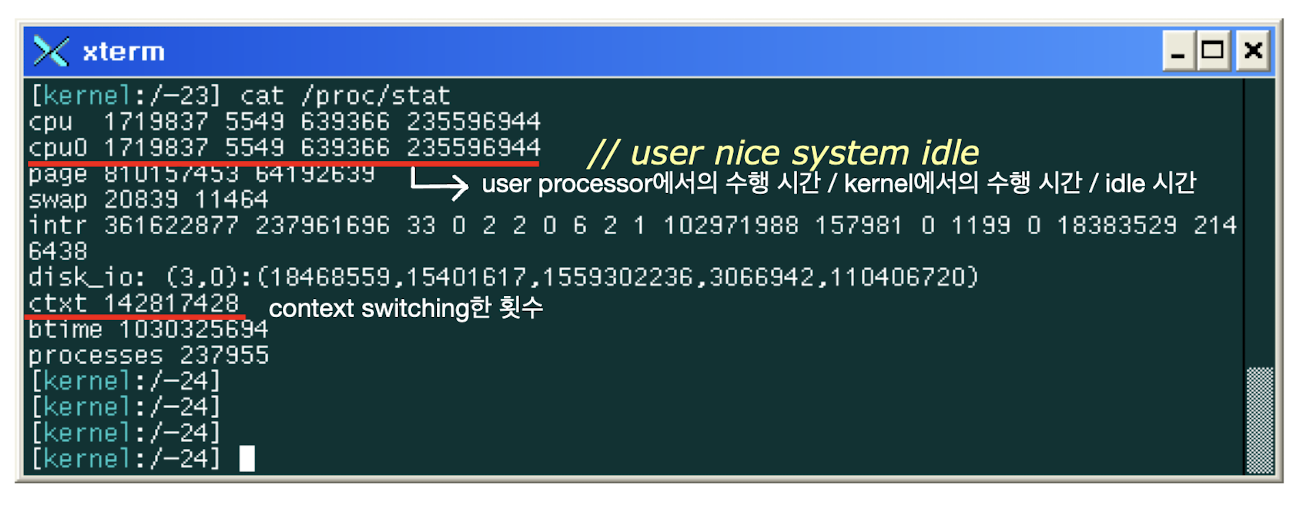
(nice system은 여기서 설명하면 더 헷갈리니까 넘어간다고 하심)
7. Schedulers
- Scheduler
: schedule하는 주체. 결국 이것도 OS라고 얘기하면 됨. (위에서 OS 내부에 있다고 언급함)
-과거의 분류
- Long-term scheduler (or job scheduler)
: 지금 실행시킬 프로그램이 file system에 있으니까 이 프로그램 중에 어떤 것을 메인 메모리로 올릴것인가를 결정하는.
즉 어떤 것을 ready queue로 넣을 것인가를 결정하는것.
-> 실행 요청이 들어온 프로그램이 10개가 있는데 메모리에는 5개밖에 못 올리는 상황. 그러면 어떤 5개를 메인 메모리에 올릴것인가가
Long-term scheduling
- Short-term scheduler (or CPU scheduler)
: 10개 중 5개가 메인 메모리로 올라왔으면 이 중에 실제 어떤 걸 CPU에다가 놓고 실행시킬 것인지를 고르는 것.
- Medium-term scheduler (or swapper)
: 지금 10개가 있는데 이중에 5개를 올려놓고 실행을 해. 근데 이 5개도 너무 힘들어서 이 중 하나를 다시 file system으로 내려보내야돼.
그때 5개 중에 어떤 것을 file system으로 내려보낼까를 결정하는 것이 Medium term.
- 현재
하지만 현재의 운영체제는 virtual memory management라는 걸 운영체제가 제공하기 때문에
메인 메모리는 무한하다라고 생각하도록 운영체제가 서비스를 제공함.
그러니까 프로그램 실행하면 무조건 다 메인 메모리로 올라오는 것.
-> long, medium term scheduler가 없어짐. short term scheduling만 남음.
swap in, swap out - 올라왔던 걸 다시 내보내고 이런걸 swapper라고 부름.
이 swapper은 medium-term에서 변경된 것.
virtual memory management에서 다시 얘기를 하겠지만,
현재 long term scheduling의 개념은 없어지고
그냥 scheduling, 혹은 CPU scheduling, short-term scheduling이라고 부름.
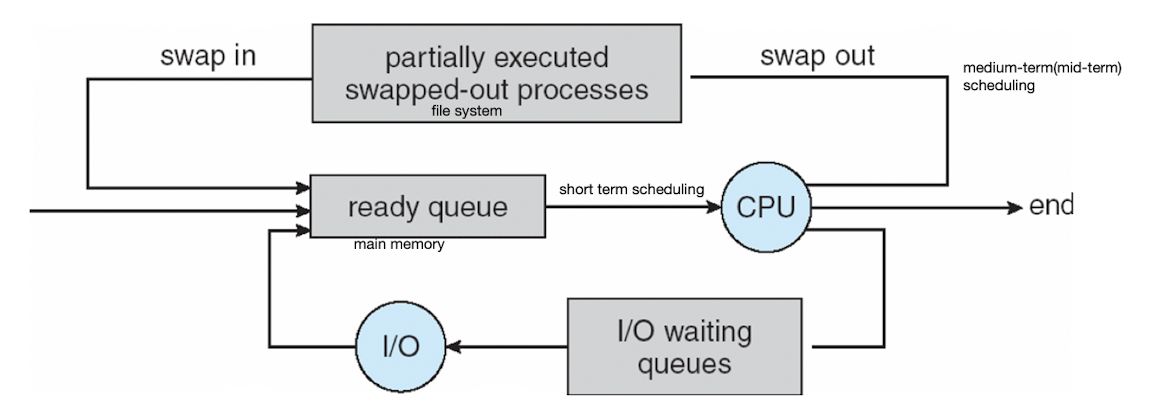
8. Representation of Process Scheduling
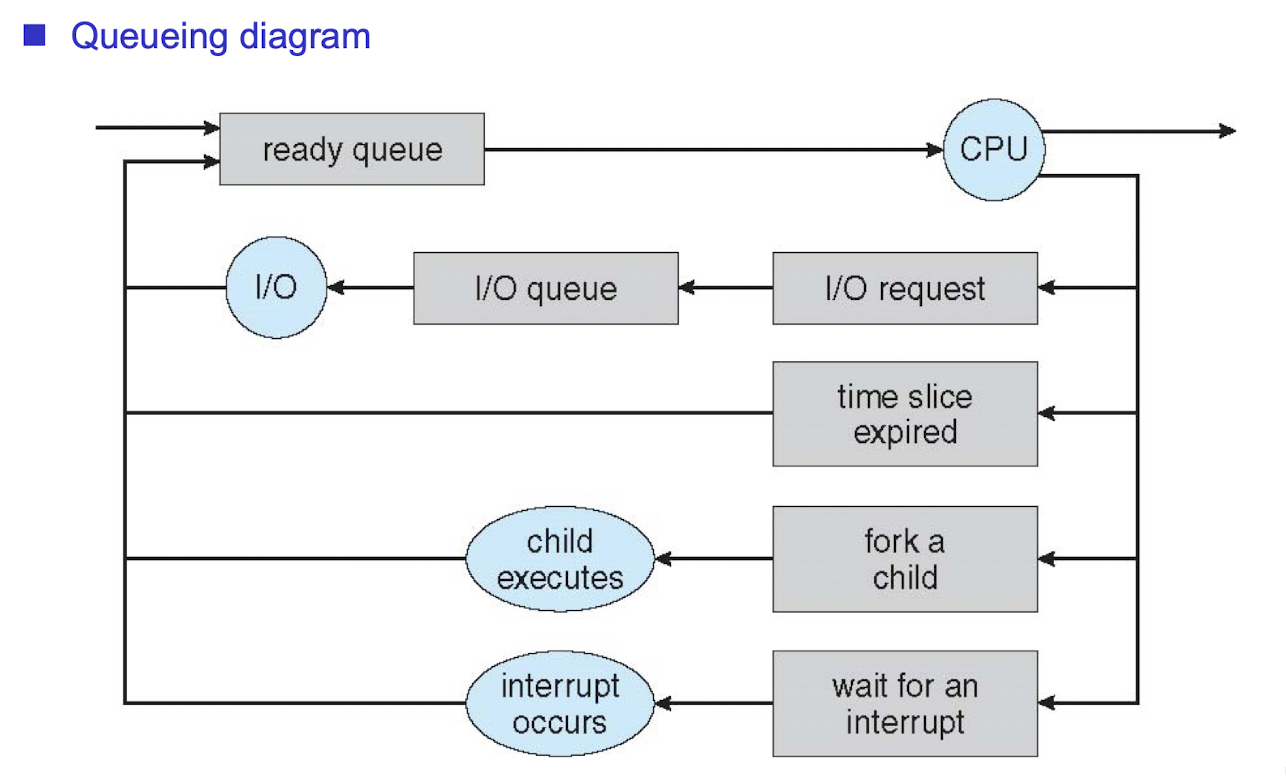
- Process에 대한 모든 정보가 저장된 PCB가 어딘가의 큐에 저장되어있다가, 다른 큐로 갔다가 하면서 돌아감.
- 동작 과정
1. 가장 처음 process가 만들어지면 ready 상태가 됨. -> ready queue에 들어감.
2. ready queue에 있다가 scheduling으로 선택 받았으면, CPU에서 수행됨. (이 땐 queue에 매달려 있지 않음)
3-1. CPU에서 수행되다가 I/O를 요청하면 CPU에서 나와서 그 I/O queue에 들어감.
(DIsk I/O 요청했으면 Disk I/O queue에 들어가고, keyboard I/O 요청했으면 keyboard I/O queue에 들어가고 ..)
3-2. 자신의 time 퀀텀 (time slice)를 다 썼다. (time-sharing 에서!) -> 바로 ready queue로 들어감.
... 기타 등등
ㄴ> 이렇게 프로세스가 어떤 queue에 들락날락하면서 실행이 된다는 것을 보여줌.
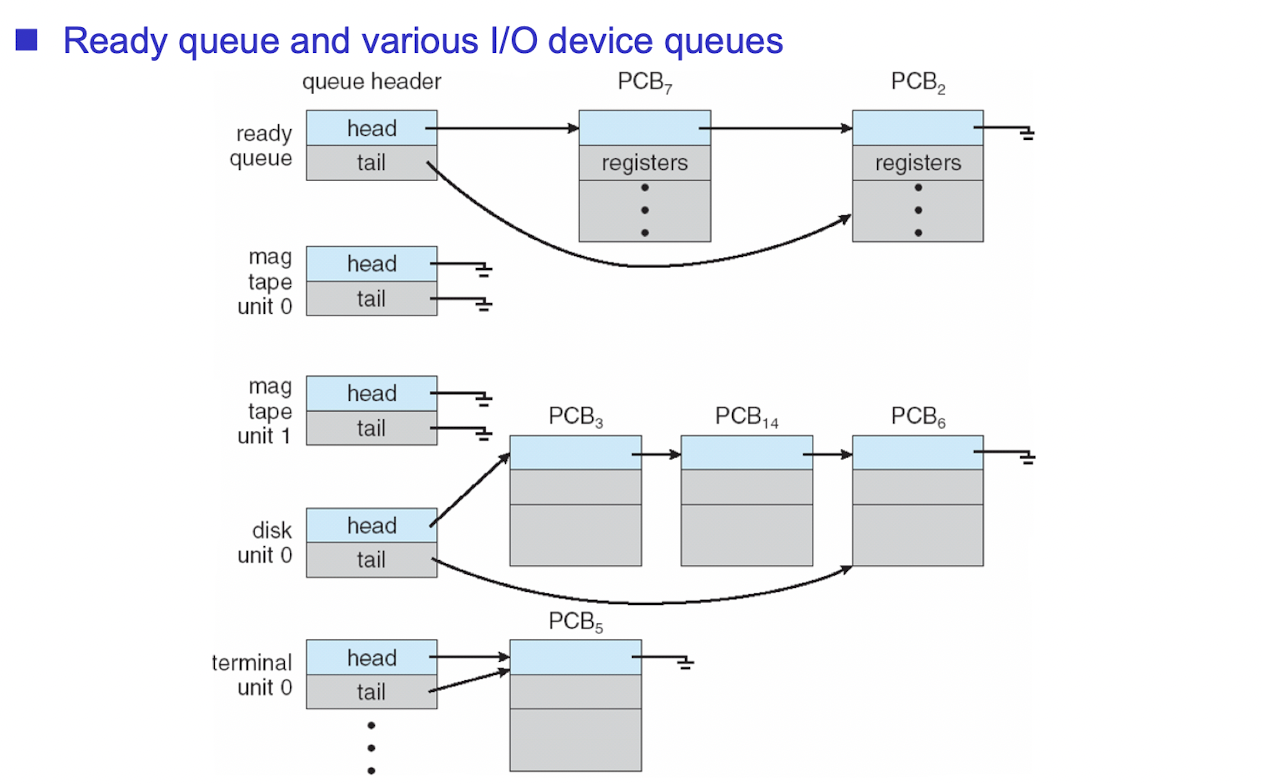
어느 순간엔 해당 프로세스가 queue에 매달려 있음을 보여줌.
그게 ready queue가 됐든, tape이라는 device의 queue가 됐든, disk라는 device의 queue .. 등
terminal은 여기서는 keyboard라고 생각하면 됨.
(원래 monitor과 keyboard 두 가지를 합해서 terminal 또는 console이라고 표현하기는 함.)
이렇게 큐들을 왔다갔다하면서 실행됨을 보여주는 그림.
*9. Example of Multiprocessing
- 문제
: 현재 여러분이 mp3 player를 켜놓고 hwp를 editing 하고 있다. 이때 컴퓨터와 운영체제 안에 일어나는 작업들에 대해 설명하시오.
ㄴ> 전통적인 중간고사 1번임. 이걸 이해하는 것이 중요합니다.
* 운영체제 / hwp / MP3 Player 가 번갈아가면서 수행될 것. (+ idle process)
* CPU에서는 어느 하나만 실행되어야겠지.

'3-2 > 운영체제' 카테고리의 다른 글
| OS - Ch03.Processes (2) (0) | 2023.03.30 |
|---|
